sw사관학교 정글 과정중 pintos project 2 진행중에 구현한 fork 의 과정을 추척하는 글을 작성 해보려고 한다.
목차
- pintos에서의 fork
- fork 과정 추적
- 1. userprogram 에서 fork 함수 호출
2. lib/user/syscall.c 에서의 처리
3. syscall-entry.S
4. userprog/syscall.c 의 syscall_handler 함수
5. userprog/process.c 의 process_fork()
6. threads/thread.c thread_create() 함수
7. do_fork
8. 다시 process_fork
- 1. userprogram 에서 fork 함수 호출
- 결론
pintos에서의 fork
Pintos에서 ‘fork’ 구현 목표는 부모 프로세스의 주소 공간을 정확하게 복사하여 자식 프로세스에 할당하는 것이다.
- fd 복제: 부모 프로세스의 fd를 자식에게도 복사.
- 주소공간 복사: pintos는 페이지 단위로 메모리를 관리하므로, 각 페이지를 자식 프로세스의 페이지에 복사
- CPU 상태 복제: 부모 프로세스의 cpu 레지스터 상태를 자식 프로세스에게 복사. >> (자식 프로세스가 부모 프로세스가 중단된 지점부터 실행을 계속 할 수 있도록 하기위해)
- 자식 프로세스의 실행: 모든 복사가 완료 된 후, 자식 프로세스는 스케줄러에 의해 레디 큐에 추가됨.
개인적으로 과정 (3.) 이 헷갈렸었다. 시스템 콜 핸들러가 동작하기 직전의 부모 프로세스의 cpu 레지스터 상태를 복사해야 함에 주의해야한다. 후술 하겠지만 이는 thread 구조체의 tf 에 값이 아니다!!!!
- 주소공간 복사의 경우 쓰기 시 복사 (copy-on-write) 기법을 사용해 메모리 사용을 높일 수 있지만, 우선 우리는 무조건 다 복사하도록 구현했다.
fork 과정 추적
1. userprogram 에서 fork 함수 호출
fork 가 언제 일어나는가? 유저 프로그램에서 fork() 함수를 호출(사용)했을 때 동작을 시작한다. 우리의 핀토스 과제에서는 테스트 케이스로 유저프로그램이 구현되어있다.
해당 과정에서는 tests/userprog/fork-onec.c 파일을 예시로 작성하겠다.
1 | /* Forks and waits for a single child process. */ |
fork(“child”) 로 시스템 콜을 호출한다.
2. lib/user/syscall.c 에서의 처리
1 |
|
해당 파일의 1. 에서의 fork(“child”) 는 위 파일의 **fork ()**를 만나 syscall1 매크로를 통해 가공되어 syscall 함수를 호출한다.
fork(“child”) >>> syscall1 (2, “child”) >>> syscall ( 2, “child”, 0, 0, 0, 0, 0)
어셈블리언어를 보면 해당하는 인자들을 레지스터리 값에 넣고 syscall을 부른다.
syscall을 부르면 MSR_LSTAR 이라는 주소를 찾아가 그 주소에 담긴 값(함수주소)을 실행한다.
<userprog/syscall.c>
1 |
MSR_LSTAR는 위와 같이 선언되어있다.
해당값에는 어떤 함수가 매핑되어있을까?
바로
<userprog/syscall.c>
1 | void |
해당 부분을 통해 MSR_LSTAR 주소에 syscall_entry 함수 주소를 넣어주었기 때문에 syscall 을 부르면 userprog/syscall-entry.S 가 실행된다.
3. syscall-entry.S
해당 파일의 코드가 실행이 되면 어떤일이 일어나는가?
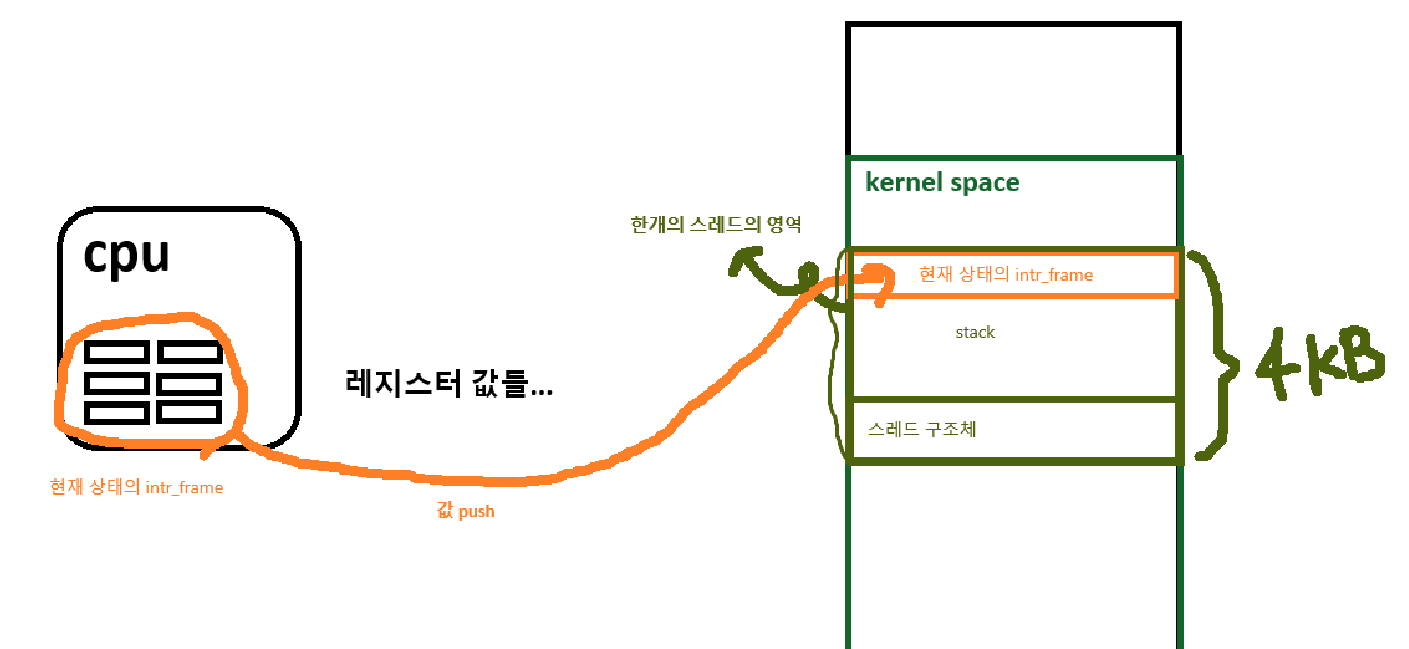
<그림 syscall-entry.S 파일이 하는 일>
위 그림처럼 현재 실행중이던 부모 프로세스의 레지스터 값들을 부모 프로세스의 (커널)스택영역 상단에 넣는다.
struct thread->tf 에 넣는 것이 아니다!!
thread 구조체의 tf 에는 언제 값을 저장하는가? 바로 스케줄링이 일어나서 문맥전환 context switching 이 일어날때 스레드 구조체의 tf 에 값을 저장한다. 그러니 tf 에 있는 intr_frame 값들은 현재 최신 상태의 (직전상태의) cpu 실행 값들이 아니다. 그래서 만약 tf 값을 자식 프로세스에게 복사한다면 fork 이전 시점의 실행과정을 복사하게 될 수도 있어서 tf 값이아니라 부모스레드 커널 스택영역의 최상단의 intr_frame 값을 복사해야한다.
위 과정이 끝난후 (해당 파일 46라인 참조) syscall_handler를 호출한다.
4. userprog/syscall.c 의 syscall_handler 함수
1 | void syscall_handler(struct intr_frame *f UNUSED) { |
이전 과정에서 fork를 할 스레드(부모) 의 커널 스택 최상단에 intr_frame을 넣었고 해당 함수의 인자로(*f) 넘어왔다.
switch 문에 fork 부분에 걸려서 우리가 구현한 fork()함수가 실행된다.
1 | pid_t fork (const char *thread_name) { |
thread_name 이 f->R.rax 이므로 **pg_round_up(&thread_name)**를 하게 되면 해당 스레드(fork를 할 스레드, 부모 스레드) 영역의최상단이 나오고 최상단에는 직전의 cpu 상태를 저장했다. 그 주소에서 intr_frame 사이즈 만큼 주소를 내려주면 *f의 주소가 나온다!!!
근데 그냥 처음부터 인자로 주면될텐데 왜 인자 하나로 구현이 되어있었을까? 이에 대한 답은 아직 못구했다.
이렇게 구한 **f(fork 를 하기 직전의 cpu 상태 정보)**를 process_fork 인자로 넘겨주면된다.
5. userprog/process.c 의 process_fork()
1 | tid_t process_fork(const char *name, struct intr_frame *if_ UNUSED) { |
위 함수로 오게되어 우선 자식이 될 스레드를 생성한다. 그런데 이제 do_fork 함수 주소와 if_ (방금 넘겨준 fork하기 직전까지의 cpu 상태정보)를 담아서 생성한다.
thread_create() 로 가보자
6. threads/thread.c thread_create() 함수
1 | tid_t thread_create(const char *name, int priority, thread_func *function, void *aux) { |
해당 코드로 오면 중간 부분을 보면
1 | t->tf.rip = (uintptr_t)kernel_thread; |
function == do_fork 함수 주소
aux == if_ 주소
를 넘겨주는데 rip 레지스터는 cpu가 다음으로 실행할 명령의 위치이다. 그래서 해당 스레드가 실행되면 kernel_thread라는 함수를 실행하게 되는데 그곳을 잠시보면 (threads/thread.c)
1 | static void kernel_thread(thread_func *function, void *aux) { |
위와 같은 함수를 실행하고 보면 넘겨받은 funtion에 인자를 넣어 실행한다. 고로 해당 스레드 create이 완료되고 스케줄링되어 실행되면 do_fork(if_)를 실행하게 되는것이다!!!!
잠시 넘어가서 thread_create아래를 더보면 fd 테이블을 할당받고 stdin, stdout, stderr를 설정해준다.
그리고 현재 스레드의 child list에 thread_create으로 만들고 있는 스레드의 자식 요소를 넣어준다.
현재 thread_create을 하고있는 스레드는 fork를 부른 스레드(부모) 이다. 해당 스레드가 자식을 낳는 과정이고 우선 생성하고 기본적인 셋팅을 해주고 나의 자식 리스트에 해당 생성할 스레드를 넣은 것이다.
위의 과정이 끝나고 해당 스레드는 레디큐에 들어가고 스케줄링이 시작되어 언젠가 실행될것이다.
위의 과정과 process_fork의 함수의 과정을 미리 말하자면.
- 부모 스레드가 thread_create을 통해 자식 스레드를 만들고 있다.
- 자식 스레드에게 실행되면(눈을 뜨면) do_fork(if_)를 실행하라는 명령을 담아 레디 큐에 넣고, 부모는 자식이 실행되어 do_fork를 통해 완전히 복사가 될때까지 sema에 의해 기다린다.
- 스케줄러에 의해 실행된 자식 스레드는 do_fork(if_) 에 의해 부모의 내용을 자기 자신에게 복사할 것이다. 복사가 실패하던 성공하던 do_fork가 끝나면 자식은 부모의 sema를 풀어준다.
- 3번 과정이 끝나기 전까지 부모 스레드는 sema 에 의해 기다리고 있다가 3번에 의해 풀려나 자식이 온전히 생성되었는지 확인한 후 값을 반환한다.
7. do_fork
1 | static void __do_fork(void *aux) { |
자식 스레드가 실행이되면 _do_fork() 함수를 실행하게된다 받은 인자는 부모의 cpu 상태 값들이다.
부모 테이블의 복사를 위해 부모 스레드 구조체 주소를 알아내야한다. 넘겨받은 인자 aux는 부모 스레드 영역에 있는 주소이므로 해당 주소를 페이지 단위로 내림 (pg_round_down) 하면 부모 스레드의 구조체 주소가 나오게 된다.
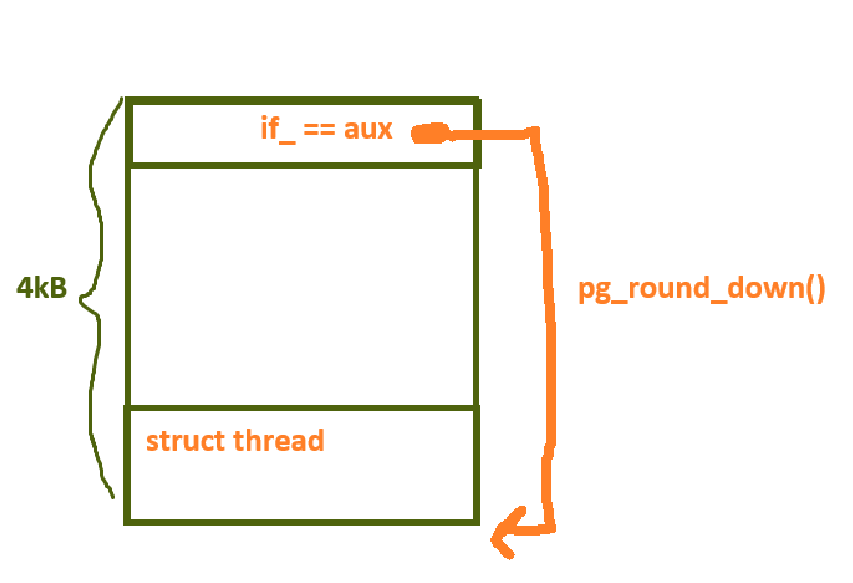
넘겨 받은 부모의 if_ 값을 memcpy로 do_fork내에서 선언한 if_ 에 복사해주고 자식 fork() 가 반환할 값인 0을 rax에 담아준다. 모든 과정 즉, 부모의 내용을 전부 복사하는 것에 성공했다면 부모의 세마를 풀어주고 do_iret에 방금까지 만든 if_ 값을 넣어 cpu를 자신을 부모에게 복사한 상태와 똑같은 상태로 만들어 일을 하기 시작한다. (부모와 똑같은 시점에 똑같은 일을 하기 시작함)
만약, 복사가 실패했다면 자신의 종료상태를 -1로 바꿔주고 (기다리고 있던 부모가 해당 표식을 보고 자식생성 실패를 인식함!!) 부모의 세마를 풀어주고 스레드를 종료한다.
8. 다시 process_fork
1 | sema_down(&child -> fork_sema); // 자식이 메모리에 load될 때까지 기다림(blocked) |
자식의 sema_up을 통해 다시 윗부분의 코드가 (부모) 실행된다. 부모는 자식이 제대로 생성되었는지 if 문으로 확인하고 에러 또는 자식의 tid를 반환한다.
결론
위와 같은 긴 과정을 지나 우리의 fork 가 실행이 되었다 성공적으로 진행되었다면
1 | pid = fork("child"); |
이 수행될것이다.
fork 함수는 나와 똑같은 주소 공간과 파일을 열고있는 새로운 프로세스를 만드는 것이다. 나와 똑같지만 다른 메모리를 사용하는 (공유하기도 하지만!!) 또다른 쌍둥이를 만드는 것이고 분기가 생기는 것이다.
모든 것을 복사한뒤에 해당 자식을 실행할 줄 알았지만 복사하라는 명령을 쥐어 준채 실행시키는 것과 나의 (부모) 상태를 복사해야 하는데 그값은 thread 구조체의 tf가아니라 thread kernel stack 상단에 위치했다는 점이 중요했다.
pintos-kaist project 2 userprogram syscall branch 링크 👈👈 구경오세요!

